How Python’s Memory Model Works: From Stack to Heap
Understanding Python's memory model is crucial for writing efficient, performant code. As developers, we often take for granted how Python handles memory allocation and deallocation behind the scenes. Understanding Python’s memory model is essential for anyone aiming to write efficient, robust code. Python’s approach to memory management is both powerful and unique, blending automation with mechanisms that allow for optimization and debugging when needed. In this post, we’ll break down Python’s memory model, demystifying what happens “under the hood” from the stack to the heap, and provide practical insights for professionals and enthusiasts alike.

Overview
Python abstracts away manual memory management, but under the hood it still relies on well-defined structures. In CPython, the default Python implementation, all objects (like numbers, strings, lists, etc.) are stored in a private heap managed by the interpreter. The Python memory manager handles allocation on this heap (including caching and pooling) so that the programmer doesn’t have to call malloc or free directly. In contrast, the call stack is used to keep track of active function calls: each function invocation creates a stack frame containing references to local variables and parameters. In other words, names and references live on the stack, while the actual objects and data live on the heap. This model makes Python a stack-based virtual machine: Python bytecode pushes object references (not raw values) onto an evaluation stack to perform operations.
Why Memory Management Matters?
Memory management is a foundational aspect of programming that directly impacts performance, stability, and scalability of your applications. Poor memory management can lead to slowdowns, crashes, or even security vulnerabilities. While Python automates much of this process. Understanding its memory model empowers you to write more efficient code and troubleshoot complex issues with confidence.
Python Memory Architecture: Stack vs Heap
Python's memory management system is built on a clear separation between two primary memory regions: the stack and the heap. This architectural design is fundamental to how Python handles different types of data and operations. Python organizes memory into two main regions:
1. Stack Memory:
Stores function calls, local variables, and control flow information. The stack is responsible for storing temporary data such as local variables, function parameters, and method calls. It operates on a Last-In-First-Out (LIFO) principle, meaning the most recently added items are removed first. When a function is called, Python creates a new stack frame to store local variables and function-specific information. Once the function returns, this stack frame is popped off the stack, and the memory is immediately reclaimed.
In other words, python keeps track of function calls. Each time you call a function, the interpreter pushes a new frame on the stack, containing that function’s local variables and parameters. When the function returns, its frame is popped off the stack. Stack allocation is static and fast: the size of each frame is known at compile time (since it depends on the number of local variables and parameters). Stack memory is automatically managed (it’s tied to the execution flow), so you don’t need to free it manually. For example, when Python executes a func() call, it allocates a new frame on the stack, assigns argument references to parameters, executes the body, and then removes the frame upon return.
Example:
def foo(): x = [1, 2, 3] # 'x' is a local variable (stack); the list is an object (heap) return x result = foo() # 'result' now references the same list object
Here, x exists on the stack during foo()’s execution, but the list [1, 2, 3] lives on the heap. When foo() returns, x is gone, but the list persists because result now references it.
2. Heap Memory:
Stores dynamically allocated objects, lists, dictionaries, class instances, etc. The heap is where Python stores all objects and data structures. Unlike the stack, the heap is not organized in any specific order and is managed by Python's sophisticated memory manager and garbage collector. All Python objects, whether they're integers, strings, lists, or custom class instances, reside in what's called a private heap.
This is a large pool of memory used for dynamic allocation of objects. Whenever you create an object (like x = 42 or y = "hello"), Python allocates space for that object on the heap. Heap allocation is dynamic: objects can be created and destroyed at runtime, and the allocator (Python’s memory manager) keeps track of them. Variables on the stack simply hold references (pointers) to these heap objects. The heap is flexible but more complex: it must handle fragmentation, reuse free blocks, and implement garbage collection. In Python, the heap is private to the interpreter, meaning all object data resides there and is managed internally.
Example:
x = [5, 6, 7] # The list is created in heap memory
Here, x is a reference on the stack, pointing to a list object on the heap. If you assign y = x, both x and y reference the same heap object.

Figure-1: Python Stack vs Heap Memory Architecture
Python Stack vs Heap: Quick Comparison
| Stack | Heap | |
|---|---|---|
| Purpose | Function calls, local variables | Objects, data structures |
| Lifetime | Short-lived (per function call) | Longer-lived (until no references remain) |
| Management | Automatic (LIFO) | Automatic (via garbage collection) |
| Allocation Speed | Very fast | Slower (but flexible) |
This division is managed by Python’s memory manager, which automates allocation and deallocation, freeing developers from manual memory management.
The Memory Allocation Process: A Journey Through Python's Internals
Python optimizes memory allocation using different strategies for small and large objects. When you create an object in Python, a sophisticated allocation process begins behind the scenes. Python doesn't simply request memory from the operating system for every object; instead, it uses a multi-layered approach designed for efficiency and performance.
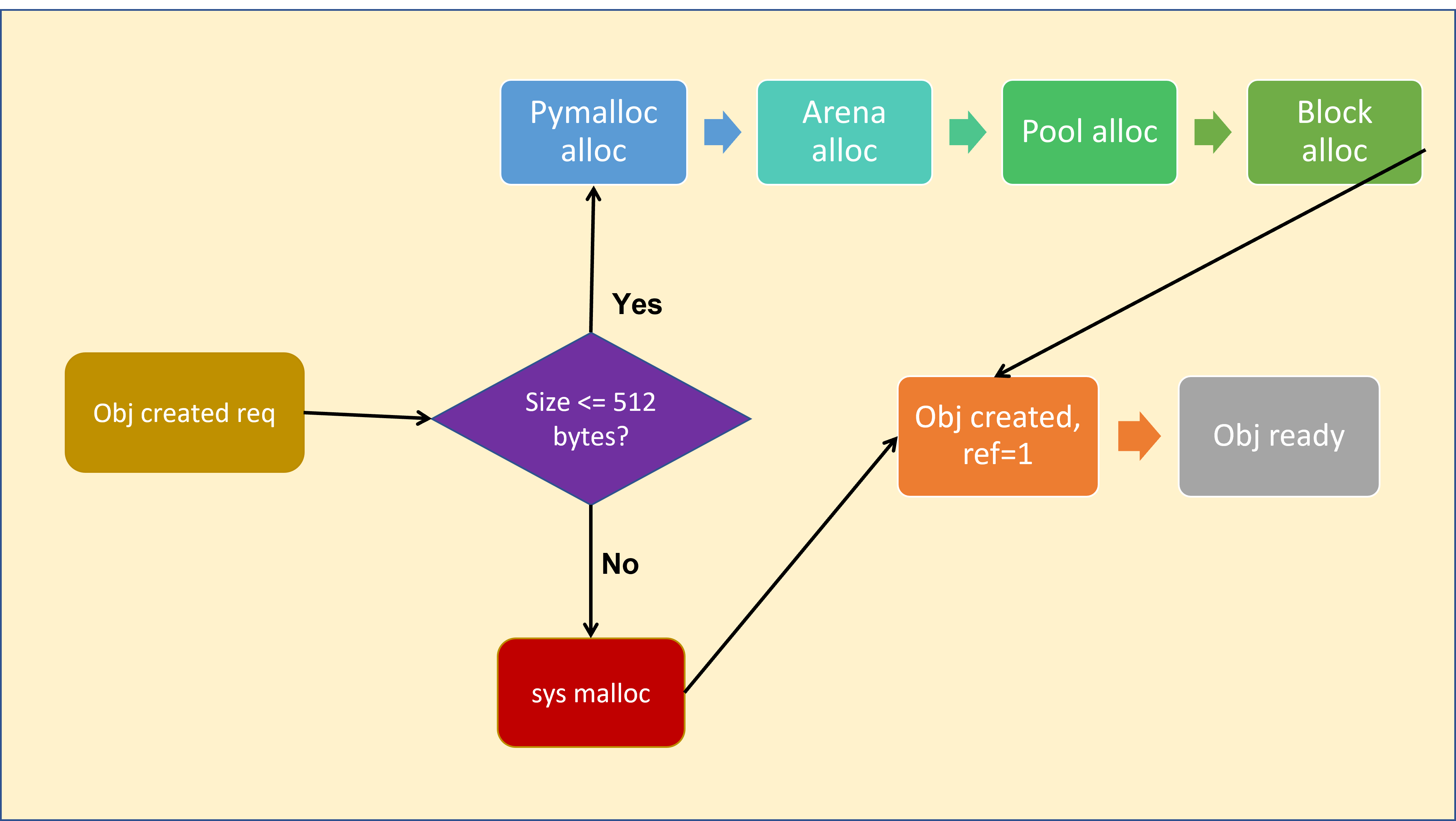
Small Objects: The Pymalloc Advantage
Pymalloc organizes memory in a three-tier hierarchy:
- Arenas are the largest units, representing contiguous memory blocks of 256 KiB on 32-bit platforms or 1 MiB on 64-bit platforms. These are obtained directly from the system allocator and serve as the foundation for all smaller allocations.
- Pools are 4 KiB subdivisions of arenas. Each pool is dedicated to objects of a specific size class, and pools are organized into linked lists based on their current state (empty, partially full, or full).
- Blocks are the smallest units within pools. They're allocated in multiples of 8 bytes, starting from 8 bytes and going up to 512 bytes. When you request memory for a small object, Python rounds up the size to the nearest multiple of 8 bytes and allocates a block of that size.
This hierarchical approach provides several advantages. It reduces fragmentation by grouping similar-sized objects together, improves cache performance by keeping related data close in memory, and minimizes the overhead of frequent small allocations.
Large Objects: Direct System Allocation
Reference Counting: The Foundation of Memory Management
When you create a reference to an object, its reference count increases. When a reference goes out of scope or is explicitly deleted, the reference count decreases. The moment an object's reference count drops to zero, Python immediately deallocates its memory.

import sys # Create an object a = [1, 2, 3] print(sys.getrefcount(a)) # Output: 2 (note: getrefcount adds its own reference) # Create another reference b = a print(sys.getrefcount(a)) # Output: 3 # Delete a reference del b print(sys.getrefcount(a)) # Output: 2 # Delete the last reference del a # The list object is now immediately deallocated
This mechanism is incredibly efficient for most scenarios because it provides immediate cleanup of unused objects without waiting for a garbage collection cycle.
The Challenge of Circular References
While reference counting is highly effective, it has one significant limitation: circular references. When two or more objects reference each other, their reference counts never drop to zero, even when they're no longer accessible from the rest of the program.
class Node: def __init__(self, value): self.value = value self.ref = None # Create a circular reference node1 = Node("A") node2 = Node("B") node1.ref = node2 node2.ref = node1 # Even after deleting our references, the nodes still reference each other del node1 del node2 # The objects won't be cleaned up by reference counting alone
This is where Python's garbage collector becomes essential.
The Garbage Collector: Breaking the Cycles
Python's garbage collector is specifically designed to handle circular references that reference counting cannot resolve. It uses a generational garbage collection approach, which is based on the observation that most objects die young. Python’s garbage collector periodically scans for such cycles and frees them.
Generational Collection Strategy
The garbage collector organizes objects into three generations:
- Generation 0: Newly created objects start here. This generation is collected most frequently since new objects are most likely to become unreachable quickly.
- Generation 1: Objects that survive one garbage collection cycle are promoted to this generation. It's collected less frequently than Generation 0.
- Generation 2: Long-lived objects that have survived multiple collection cycles reside here. This generation is collected least frequently.
The collection process is triggered when the number of allocations exceeds the number of deallocations by certain thresholds. The default thresholds are typically (700, 10, 10), meaning Generation 0 is collected when there are 700 more allocations than deallocations, Generation 1 when Generation 0 has been collected 10 times, and so on.
Cycle Detection Algorithm
When garbage collection runs, Python uses a sophisticated algorithm to detect unreachable cycles. It temporarily removes all external references to objects and then traces through the remaining references to identify which objects are still reachable. Objects that can't be reached through this process are considered garbage and are cleaned up.
Object Interning: Python's Memory Optimization Secret
Python employs a clever optimization technique called interning to reduce memory usage for commonly used immutable objects. This technique involves storing only one copy of frequently used objects and reusing them whenever the same value is needed.
Integer Interning
Python automatically interns integers in the range of -5 to 256. This means that when you create variables with values in this range, they all reference the same object in memory:
a = 100 b = 100 c = 100 print(id(a) == id(b) == id(c)) # True - they all reference the same object print(a is b is c) # True
However, for integers outside this range, Python creates separate objects:
x = 1000 y = 1000 print(id(x) == id(y)) # False - separate objects print(x is y) # False
This optimization is particularly effective because small integers are used frequently in typical programs for loop counters, array indices, and simple arithmetic operations.
String Interning
Python also interns certain strings automatically, particularly those that look like identifiers (containing only letters, digits, and underscores) or contain ASCII characters. This optimization speeds up dictionary lookups and reduces memory usage for commonly used strings.
Memory Optimization Strategies
Understanding Python's memory model enables you to write more efficient code. Here are practical strategies you can employ:
1. Use Built-in Data Structures Wisely
Python's built-in data structures are highly optimized for memory usage and performance. For example, sets are more memory-efficient than lists for membership testing, and tuples use less memory than lists for immutable collections.
2. Leverage Generators for Large Datasets
Reuse objects where possible, and be mindful of large data structures. Instead of creating large lists that consume significant memory, use generators that produce values on-demand:
# Memory-intensive approach large_list = [x**2 for x in range(1000000)] # Memory-efficient approach large_generator = (x**2 for x in range(1000000))
Generators are particularly valuable when processing large datasets because they maintain a small memory footprint regardless of the data size.
3. Optimize Object Structures
When creating custom classes, consider using __slots__ to limit the attributes and reduce memory overhead:
class OptimizedClass: __slots__ = ['x', 'y', 'z'] def __init__(self, x, y, z): self.x = x self.y = y self.z = z
This approach prevents Python from creating a dictionary for each instance, significantly reducing memory usage when you create many instances.
4. Profile Memory Usage
Use tools like memory_profiler, tracemalloc and objgraph to identify memory bottlenecks and leaks in your applications:
from memory_profiler import profile @profile def memory_intensive_function(): # Your code here pass
These tools provide detailed insights into memory allocation patterns and help you identify optimization opportunities.
Advanced Memory Management Concepts
1. Manual Garbage Collection Control
While Python's automatic garbage collection is generally efficient, there are scenarios where manual control can be beneficial. The gc module provides functions to disable, enable, and trigger garbage collection:
import gc # Disable garbage collection during bulk operations gc.disable() # Perform memory-intensive operations gc.enable() # Manually trigger garbage collection gc.collect()
This approach can be useful during bulk data processing where you want to minimize garbage collection overhead.
2. Memory Pools and Fragmentation
Python's memory manager maintains pools of memory blocks to reduce fragmentation and improve allocation speed. Understanding this can help you design applications that work well with Python's memory management:
- Objects of similar sizes are grouped together to reduce fragmentation
- The memory manager tries to reuse freed blocks before allocating new ones
- Large objects are handled separately to avoid fragmenting the small object pools
3. Weak References
Use weak references (weakref module) or explicit del statements to help the garbage collector. For scenarios where you need to reference an object without affecting its reference count, Python provides weak references:
import weakref obj = SomeClass() weak_ref = weakref.ref(obj) # The weak reference doesn't prevent garbage collection del obj # obj can now be garbage collected even though weak_ref exists
This is particularly useful for implementing caches or observer patterns where you don't want to prevent object cleanup.
Best Practices for Memory-Efficient Python Code
1. Avoid Global Variables
Globals can keep objects alive longer than necessary, increasing memory footprint. Large global variables persist throughout your program's lifetime and can't be garbage collected until the program terminates. Instead, use local variables and pass data as function parameters when possible.
2. Use Context Managers
Context managers ensure that resources are properly cleaned up even if exceptions occur:
with open('large_file.txt', 'r') as f: data = f.read() # File is automatically closed here, freeing associated memory
3. Consider Alternative Data Structures
For specific use cases, alternative data structures can provide significant memory savings:
- Use array.array for homogeneous numeric data instead of lists
- Use collections.deque for frequent insertions and deletions at both ends
- Use numpy arrays for numerical computations
4. Monitor Memory Usage in Production
Implement memory monitoring in production applications to detect memory leaks or unusual usage patterns:
import psutil import os def get_memory_usage(): process = psutil.Process(os.getpid()) return process.memory_info().rss / 1024 / 1024 # MB
The Future of Python Memory Management
Python's memory management continues to evolve with each version. Recent improvements include:
- Enhanced garbage collection algorithms that reduce pause times
- Better handling of large object allocation and deallocation
- Improved memory pool management for better performance
- More sophisticated heuristics for garbage collection triggering
Understanding these fundamentals provides a solid foundation for writing efficient Python code and troubleshooting memory-related issues. As Python continues to evolve, these core concepts remain relevant and essential for serious Python developers.
Conclusion
In summary, Python’s memory model distinguishes between the stack (function call frames with references) and the heap (dynamically allocated objects). The interpreter automatically handles both: pushing and popping frames on the stack as you call and return from functions, and allocating/freeing objects on the heap via reference counting and garbage collection. While these details are mostly transparent, knowing them is crucial when reasoning about performance or debugging memory issues. By visualizing variables as pointers on a stack that reference objects on the heap (as in the diagrams above), developers can better grasp how Python manages data in memory. With this understanding, you can write more efficient Python code and diagnose unexpected behaviors (like why changing a mutable object inside a function affects the caller) with confidence.
Python's memory model represents a sophisticated balance between automatic memory management and performance optimization. By understanding how the stack and heap work together, how reference counting provides immediate cleanup, and how the garbage collector handles complex scenarios, you can write more efficient and reliable Python code. The key takeaways from this exploration are:
- Python's memory architecture separates stack (temporary data) from heap (objects)
- Reference counting provides immediate cleanup for most objects
- Garbage collection handles circular references through generational collection
- Pymalloc optimizes small object allocation through arenas, pools, and blocks
- Object interning reduces memory usage for common values
- Understanding these mechanisms enables better code optimization and debugging
Whether you're building web applications, data processing pipelines, or machine learning models, this knowledge of Python's memory management will serve you well in creating efficient, scalable solutions.
Python’s memory model, combining the stack for function calls and references, the heap for object storage, and automated garbage collection, strikes a balance between developer productivity and runtime efficiency. By understanding these mechanisms, you can write more efficient, reliable code and troubleshoot performance issues with greater clarity. Whether you’re building high-performance web apps, data science pipelines, or teaching the next generation of developers, a solid grasp of Python’s memory model is a valuable asset. Keep exploring, keep optimizing, and let Python’s memory management work for you!


